study:oracle:newmassdatabasesolutions:tableindexseparation
목차
테이블과 인덱스의 분리형
분리형 테이블의 구조
Table, Index Structure
- 테이블과 인덱스 분리 : 관계형 데이터베이스에서 일반적인 구조.
- 장점 : 대용량의 데이터 관리 용이, 데이터 저장시 인덱스의 영향을 받지 않음
- 분리형 테이블의 구조
- 데이터베이스 구조
Database Structure
- [그림] Database Structure(ORACLE 9i Database Administration Fundmentals I)
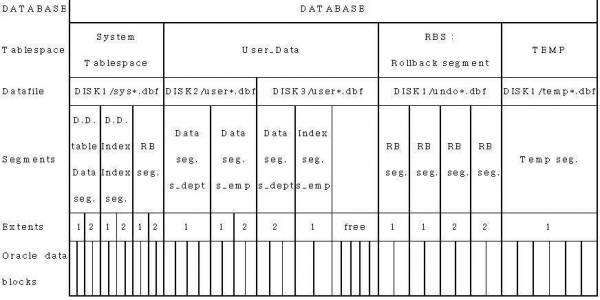
- D.D. : Data Dictionary
- R.B. : RollBack
- tablespace : 논리적인 저장구조(부지)
- segment : 테이블스페이스를 용도별로 구분(건물 부지, 운동장 부지)
- datafile : 물리적인 데이터파일(대지)

Tablespace Structure
- [그림] Tablespace Structure
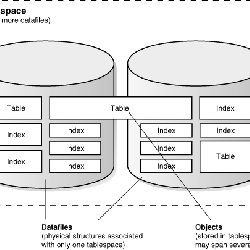
- 파티션된 테이블은 2개 이상의 테이블스페이스에 걸쳐서 저장 될 수 있다.
- 개별 파티션이나 파티션되지 않은 테이블들은 반드시 하나의 테이블스페이스에만 저장된다.

ROWID
| Rowid(주소. 논리적인 값) = 오브젝트 번호 + 데이터 파일 번호(테이블스페이스당 일련번호) + 블록번호 + 슬롯번호 |
|---|
| Rowid 위치 | 인덱스 |
|---|---|
| 데이터 파일 번호 | 상대적인 번호. 테이블스페이스내에서 부여되는 번호 |
| 오브젝트 번호 | 유일한 번호. rowid를 짧게 구성할 수 있게 한다. |

[Fig 1. ROW Piece]
ROWID와 로우의 이동
- 블록내에서 로우의 이동
- ROWID에는 로우의 위치정보가 있는것이 아니라 슬롯(블록내 위치)번호가 저장되어 있으므로,
로우의 위치가 이동하더라도 블록의 변동이 없으므로 ROWID는 변동없음 - ⇒ 로우 이동시 새로운 위치값(새로운 슬롯값)만 바꿔주면 되므로 ROWID의 변경없이 이동할 수 있다.
- 다른 블록으로 이동
- 블록의 위치가 변동 되었으므로 ROWID는 변경됨
- Condensing(응축) : 여유공간이 충분하나, 한 조각으로 저장할 연결될 조각이 없어 로우를 저장 할 수 없을 경우에 자동으로 블록의 로우들을 재구성함.
- Migration(로우의 이주) : 기존 블록에 새로 옮겨갈 블록의 주소를 남겨놓고 이동하는 경우. ROWID는 변경이 없으나,액세스할 때 여러 블록을 읽어야함.
로우나 테이블을 삭제하고 다시 생성해야 로우의 이주를 해결할 수 있다. - cf) Chain : 로우의 길이가 한 블록을 넘을 경우, 필요한 공간만큼 블록을 연결해서 저장하는 데, 이를 “체인이 발생했다”라고 함.
클러스터링 팩터(clustering factor)
정의
- 클러스터링 팩터 : 인덱스의 컬럼값으로 정렬되어 있는 인덱스 로우의 순서와 테이블에 저장되어 있는 데이터 로우의 위치가 얼마나 비슷한 순서로
저장되어 있느냐에 대한 정도를 나타냄.
설명
- Good Clustering Factor = 응집이 높다
- 인덱스에서 많은 로우(row)를 액세스하더라도 테이블의 블록 액세스를 적게 하는 경우를 클러스터링 팩터가 좋다고 할 수 있다.
- 응집 : 자주 액세스하는 것들이 유사한 위치에 모여 있도록하는 것
예제

- INDEX1 : 7개의 로우를 액섹스하지만, 2개의 블록을 액섹스하므로 클러스터 팩터가 좋음
- INDEX2 : 3개의 로우를 액섹스하는데 데이터 블록은 3개나 액세스하므로 클러스터 팩터가 좋지 않음
분리형 테이블의 액세스 영향요소
넓은 범위의 액세스 처리에 대한 대처방안
| 소형테이블 | 소량의 데이터가 흩어져 있어다 하더라도, 앞서 발생한 액세스에 의해서 이미 메모리 내에 존재 할 가능성이 높다. 메모리 내에서 랜덤 액세스를 해도 부하의 부담은 크지 않다. |
|---|---|
| 중형테이블 | 데이터 저장 구조 및 액섹스 형태를 같이 고려해야한다. |
| 대형테이블 - 단순 저장형 테이블 | log성 정보를 관리하는 테이블이므로 자주 사용되지도 않고, 액섹스 형태는 다양하지 않다. 그러나, 신속한 저장을 요구하거나, 대량의 데이터가 증가될 경우 분리형 or 파티션이 적절하다. |
| 대형테이블 - 랜덤 액세스가 자주 밣생하나 액섹스형태가 다양하지 않은 경우 | 분리형이 적절 특정 부분에서 별도의 작업을 하지 않으므로 파티션이나 클러스터링을 하지 않아도 된다. |
| 대형테이블 - 데이터는 지속적으로 증가하고, 다양한 액섹스 형태를 가지는 경우 | 파티션 적용. 테이블 구조 결정이 중요 |
클러스터링 팩터 향상 전략 : 테이블 재생성
테이블 재생성 하는 목적
- 응집도를 높이고 인덱스의 저장 구조 개선, 수행속도 향상
테이블 재생성 하는 방법
- 범위 처리가 잦은 컬럼(들)로 정렬하여 저장한다.
- 범위 처리가 잦은 컬럼(들)로 정렬하여 저장하는 방법이 불가능 할 경우 : 병렬 처리로 저장
- 수행속도 향상 : 체인(chain) 감소 및 불필요한 I/O감소
- 테이블 재생성시 기존 인덱스를 제거하거나 비활성화 시킴 : 테이블 저장 속도 향상 및 인덱스 저장 밀도 향상을 위해서
study/oracle/newmassdatabasesolutions/tableindexseparation.txt · 마지막으로 수정됨: 2010/05/06 20:45 저자 starlits
별도로 명시하지 않을 경우, 이 위키의 내용은 다음 라이선스에 따라 사용할 수 있습니다: CC Attribution-Share Alike 4.0 International
